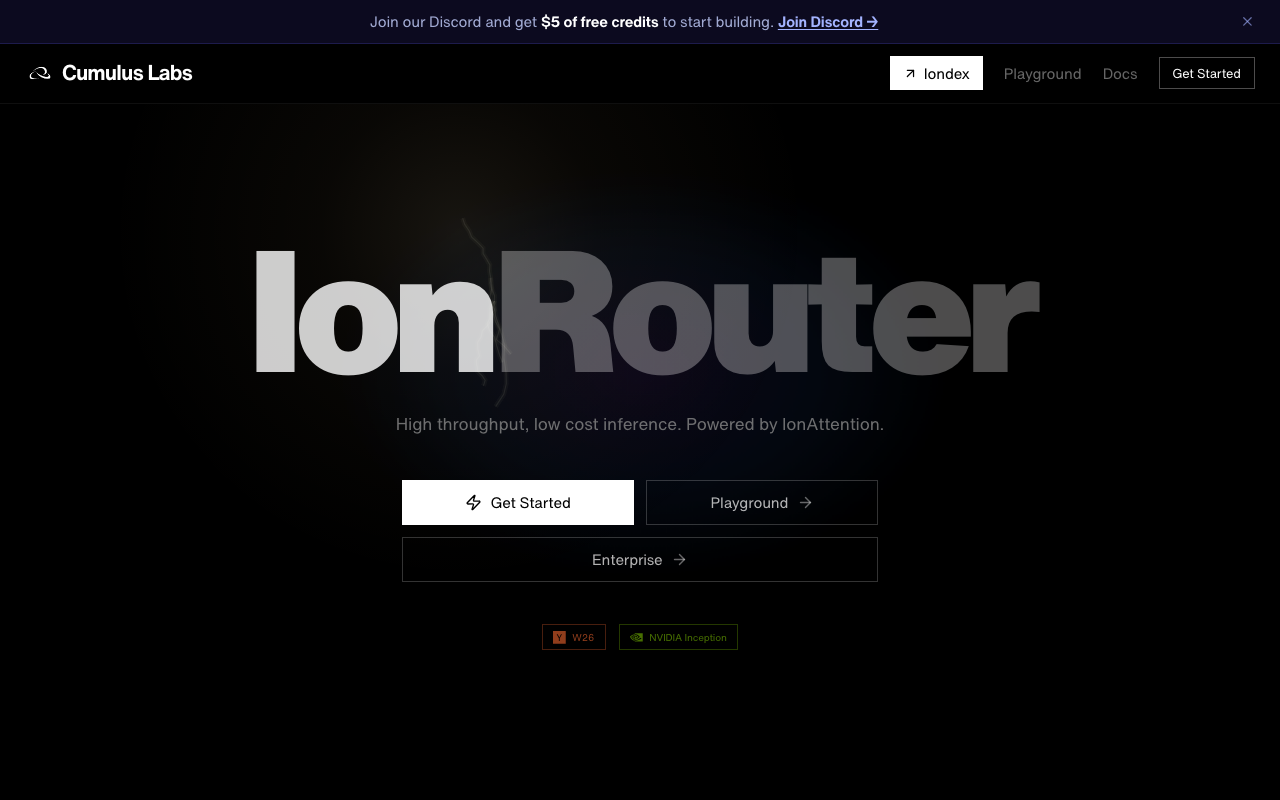
IonRouter
AI inference infrastructure company powering high-throughput, low-cost inference.
Our Take
Most inference platforms make you pay for a dedicated GPU per model, which is honestly wild when you think about it. Cumulus Labs built IonAttention — their custom inference stack — to multiplex multiple models onto a single GPU, so teams running LoRAs, fine-tuned variants, or a whole model zoo in production stop burning money on idle capacity. IonRouter ships zero cold starts and per-second billing, which sounds minor until you've been charged by the minute for GPU time you used for 12 seconds at 3am. If you're scaling multi-model infrastructure without a solve like this, you're leaving actual money on the table.
Key Facts
The people behind IonRouter
Links
Similar products worth knowing
Gumloop
AI Automation Framework for building multi-agent workflows without coding
Klipy — Does the work after every call
Proactive Sales Operating System that turns every email, meeting, and message into disciplined follow-through and reliable revenue data
Airpoint
Touchless computing with hand tracking and AI agents.
Firecrawl CLI
The complete web data toolkit for AI agents.
Want products like this in your inbox every morning?
Five products. Every morning. Written by someone who actually cares whether they're good or not. Free forever, unsubscribe whenever.